
레디스(Redis)란 무엇일까?
현재 진행하고 있는 프로젝트 BookStore 에 Redis 를 적용하기 위해 자료를 찾다가 우아한 레디스 세미나 영상을 보고 정리해보았다.
Redis 란?
Redis 는 다음과 같은 특징을 갖는 데이터 구조이다.
1) 인 메모리 기반의 데이터 저장소이다.
2) Key - Value 구조 데이터 관리 시스템으로 비 관계형이며, 쿼리 없이 데이터에 접근할 수 있다.
3) Strings, Set, Sorted-Set, Hashes, List ... 등 자료구조를 지원한다.
4) 서비스의 상황에 따라 캐시 또는 지속적인 데이터 저장소로 사용할 수 있다.
캐시의 정의
그럼 캐시는 무엇일까?캐시는 나중에 요청올 결과를 미리 저장해두었다가 빠르게 서비스를 해주는 것을 의미한다. 다이나믹 프로그래밍에서 앞의 내용을 저장해뒀다가 뒤에서 사용할 때 가져오는 것과 같은 목적이다.대표적인 예로는 팩토리얼이 있다. 20880!을 계산해두고 어딘가에 저장해뒀다면 20881!은 금방 구한다.
같은 맥락으로 서비스의 사용자가 많을 경우 모든 유저의 요청이 DB로 간다면 DB 서버에 무리가 가며, 서버의 장애와 성능 저하까지 이어질 수 있다. 이 때 캐시를 사용해 요청된 결과를 어딘가에 미리 저장해뒀다가 요청이 오면 바로 제공하면 된다.
Redis Cache 는 메모리 단 (In-Memory) 에 위치한다. 따라서 용량은 적지만 접근 속도가 빠르다. 저장하려는 데이터 셋이 주어진 메모리 크기보다 크면 디스크를 쓰는 것이 좋은 선택이다.
캐시의 구조 - 캐시는 어떻게 사용할까?
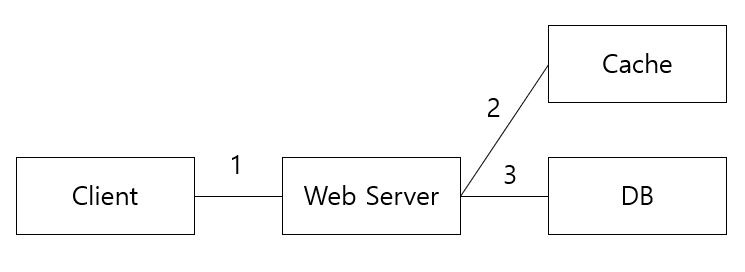
가장 일반적인 패턴은 Look aside cache 이다.
1) Web Server 는 데이터가 존재하는지 Cache 를 먼저 확인한다.
2) Cache 에 데이터가 있으면 Cache 에서 가져온다.
3) 만약 없으면, DB 에서 읽어온 데이터를 Cache 에 저장한다.
다음은 Write Back 이다.
쓰기가 굉장히 많을 경우 데이터를 캐시에 전부 저정해뒀다가 특정 시점마다 한번씩 캐시 내의 데이터를 DB에 insert 하는 방법이다. insert 를 1개씩 500번 수행하는 것보다 500개를 한번에 삽입하는 동작이 훨씬 빠름에서 알 수 있드시 write back 방식은 빠른 속도로 서비스가 가능하다.
하지만 단점도 있다.
데이터가 캐시에 있기 때문에 서버에 장애가 일어나면 손실의 가능성이 있다. 로그를 DB에 저장할 때 자주 쓰인다. 그래서 다시 재생 가능한 데이터나, 극단적으로 heavy 한 데이터에서 write back 방식을 많이 사용한다. 예를 들면 로그를 캐시에 저장하고 특정 시점에 DB 에 한번에 저장하는 경우가 있다.
Redis 의 특징
캐시로 많이 사용하는 Memcached 와 Redis 의 가장 큰 차이는 Collection 을 제공하냐의 여부이다. Redis 에서는 Collection 을 제공한다. Collection은 제공해주는 것들이 많기 때문에 개발의 편의성과 난이도에서 이점을 볼 수 있다.
랭킹 서버를 직접 구현한다고 가정해보자.
가장 간단한 방법은 DB 에 유저의 Score 를 저장하고 Score 로 order by 로 정렬 후 읽어오는 방법이다. 문제점은 가져와야 하는 데이터 수가 많아지면 디스크 접근 횟수가 많아지므로 속도가 점점 느려질 수 밖에 없다.
좋은 방법은 Redis의 Sorted Set을 이용하는 것이다. 다만 Redis 를 쓰면 메모리의 한계에 종속적이 된다. 예를 들면, 랭킹에 저장해야 할 id 가 100byte 라고 하면 1조명은 1TB의 메모리가 필요하다는 것인데, 사실 이 정도의 크기는 고민할 필요가 없다.
친구 리스트를 관리할 때 데이터를 key-value로 저장해야 한다고 가정해보자.

서로 다른 사용자가 같은 친구 리스트를 읽은 후, 친구를 추가했다고 가정해보자.
위의 표를 보면, 사용자1은 트랜잭션(T1) 안에서 친구 B를 추가했고, 사용자2는 트랜잭션(T2) 안에서 친구 C를 추가했지만, 데이터를 읽고 쓰는 순서가 보장되지 않기 때문에(Atomic 하지 않다) 최종적으로 A, C라는 결과가 나왔다.

추가적으로 시간순서 5 에서 컨텍스트 스위칭이 일어나 최종적으로 A, B라는 결과가 나올 수 있다.
이를 Race Condition이라고 한다.
그러나 Redis 는 Atomic 하다는 특징을 갖고 있어 위와 같은 Race Condition 을 피할 수 있다.
Redis Transaction 은 한번의 딱 하나의 명령만 수행할 수 있다. 이에 더하여 single-threaded 특성을 갖고 있기 때문에 다른 스토리지 플랫폼보다는 이슈가 덜하다.
하지만 이 특징이 더블클릭 같은 동작으로 insert가 두 번 일어나는 상황이 일어날 수 있기 때문에 별도의 처리가 필요하다.
Redis 는 어디에 사용해야 할까?
Redis는 Remote Data Storage 이기 때문에 여러 서버에서 같은 데이터를 공유할 수 있다. 그럼 서버가 한 대면 전역 변수를 쓰면 되지 않을까? 라는 의문이 들 수 있지만, 전역 변수는 Atomic 을 보장하지 않아 올바른 방법이 아니다.
주로 인증 토큰 저장, Ranking 보드, 유저 API Limit, 잡 큐에서 많이 사용된다.
Redis Collections
1) String
가장 일반적인 형태로, key - value 로 저장하는 형태이다.
2) Set
중복된 데이터를 담지 않기 위해 사용하는 자료구조이다. 고유한 데이터를 저장할 때 많이 사용된다.
3) List
Array 형식의 데이터 구조이다. 맨 앞과 뒤는 시간복잡도가 O(1)이지만 중간에 넣거나, 삭제는 느리다.
4) Sorted Set
유저 랭킹 보드로 사용할 수 있다.
5) Hash
Key 밑에 sub key 가 존재하는 자료구조이다.
기본적인 명령어는 레디스(Redis)의 기본 명령어에 정리하였다.
Collections 를 사용할 때 주의할 점이 있다.
하나의 컬렉션에 너무 많은 아이템을 담으면 좋지 않다. 가능하면 10000개 이하의, 몇천개 수준의 데이터 셋을 유지하는게 Redis 성능에 영향주지 않는다.
Expire 은 Collection 의 아이템 개별로 걸리지 않고, 전체 Collection 에 걸린다.
즉, 10000 개의 아이템을 가진 Collection 에 expire 가 걸려있다면, 그 시간 이후에 10000 개의 아이템이 모두 삭제된다.
Redis 운영하기
메모리 관리를 잘 하자
1) Redis 는 In-Memory Data Store 이기 때문에 물리적 메모리 이상을 사용하면 문제가 발생한다.
만약 swap 이 있다면 swap 사용할때 디스크에 접근하기 때문에 인 메모리를 사용해 성능을 높이는 레디스의 장점이 사라진다.
swap 이 없다면 oom(메모리 부족) 으로 죽을 수 있다.
2) Max Memory를 설정하더라도 이보다 더 사용할 가능성이 크다.
1 byte 만 달라고해도 jemaloc 는 페이지 단위에 의해서 메모리를 주므로 4096 byte 를 할당한다. 만약 여기서 4096 byte 를 더 요청하면 4097 byte 만 사용하고 있지만, 메모리는 8K 만큼 사용하게 되는 것이다. 이런 현상을 메모리 파편화라고 한다. 따라서 메모리 파편화가 일어나면, 레디스 사용량과 jemaloc 할당량이 달라진다.
3) 큰 메모리를 사용하는 instance 하나보다는 적은 메모리를 사용하는 instance 여러 개가 안전하다.
Redis 는 쓰기 요청이 오면 copy on write 방식으로 작동한다. Redis 는 쓰기 작업을 하면 순간 fork 를 하여 갱신할 메모리 페이지를 복사한 후 쓰기 연산을 한다. 당연히 여기서 최대 메모리를 2배 까지 사용할 수 있다. 읽기 작업은 copy on write 방식으로 동작하지 않는다.
예를 들면, 24GB 한대가 2 배 사용하면 48GB 사용하지만, 8GB 3 대에서 1 대가 2 배를 사용하게 되면, 32 GB 만 사용하게 된다.
메모리가 부족할 때는?
1) 좀 더 메모리가 많은 장비로 마이그레이션이 필요하다.
2) 데이터를 줄인다.
메모리를 줄이기 위한 설정들
1) Hash → HashTable 을 하나 더 사용한다.
2) Sorted Set → Skiplist 와 Hash Table 을 둘 다 사용한다. 값으로도 찾아야하고, 인덱스로도 찾아야하기 때문이다.
3) Set → Hash Table 을 사용한다.
하지만 Skiplist 나 Hash Table 자료구조도 많은 메모리를 사용한다.
In-Memory 특성 상, 적당한 사이즈의 데이터까지는 특정 알고리즘을 안쓰고 그냥 선형 탐색을 해도 빠르다. 따라서 1개 컬렉션에 데이터가 많다면 ziplist 를 사용하는게 속도는 조금 느려지지만 메모리는 적게 쓰는 방법이다. 실제로 메모리를 30% 정도까지 적게 사용한다. 게다가 원래 쓰는 자료구조 대신 내부적으로 ziplist 를 쓰도록 간단히 설정만 바꿔줄 수도 있다.
O(n) 관련 명령어는 주의하자
Redis 는 Single Thread 이므로 동시에 처리할 수 있는 명령 개수는 1개이다. 단순한 get / set 명령어의 경우 초당 10만개를 처리할 수 있다고 한다.
그러나 주의할 점이 있다.
Single Thread 이기 때문에 오래 걸리는 명령을 수행하면 그 뒤의 명령어들은 대기를 해야한다. 예를 들면 만약 1개에 1초가 걸리는 작업을 한다고 가정해보자. 최악의 경우 99999 개의 명령은 1초동안 그냥 대기해야 하는 것이다. 이런건 99999개의 타임아웃이 발생할 수 있는 상황이다.
대표적인 O(n) 명령어는 다음과 같다.
1) KEYS - 모든 데이터 순회
2) FLUSHALL, FLUSHDB – 데이터 전부 삭제
3) Delete Collectsions – 큰 Collections 안의 데이터 모두 삭제
4) Get All Collections – 큰 Collections 안의 데이터 모두 조회
KEY 는 어떻게 대체할까?
scan 명령을 사용하는 것으로 하나의 긴 명령을 짧은 여러 번의 명령으로 바꿀 수 있다. 짧은 명령 사에이 read 몇 만개가 처리될 수 있다.
Collections 의 모든 데이터를 가져와야할 때 어떻게 대체할 수 있을까?
Collections 의 일부만 가져오거나 큰 Collections 을 작은 여러개의 Collection 으로 나눠서 저장한다. 예를 들면, UserRanks 를 UserRank1, UserRank2, UserRank3로 나눠서 관리한다.
Redis Replication
Redis Replication 은 비동기 Replication 이기 때문에 Replication Rag 가 발생할 수 있다.
Replication
여러 개의 DB 를 권한에 따라 수직적인 구조(Master-Slave)로 구축하는 방식이다. Master 은 쓰기 작업 만을 처리하고, Slave 는 읽기 작업 만을 처리한다.
Replication Rag
Master 에 있는 데이터가 바뀌었다고 해보자. 이때 Master → Slave 로 replication 이 발생하기 직전의 틈이 발생할 수 있다. 이 때 Master 와 Slave 의 데이터가 일치하지 않는 이슈가 발생할 수 있다.
Slave 에 Replicaof 나 slaveof 명령을 통해 설정할 수 있다. 이 때에는 Master 의 host | ip, port 를 전달해야 한다.
이 상황에서는 내부적으로 Slave 가 Master 에 sync 명령을 전달한다.그럼 이 때 Master node 는 현재 메모리 상태를 저장해서 주기 위해 fork() 를 수행하여 Slave node 에 전달하는데, 이게 모든 이슈의 근원이 된다.
AWS 와 같은 클라우드의 Redis 는 좀 다르게 구현되어서, fork 없이 replication 하기 때문에 좀 느리지만 해당 부분이 안정적이다.
Redis Cluster
Cluster
DB 분산 기법 중 하나로 DB 서버를 여러 개 두어 서버 한 대가 죽었을 때 대비할 수 있는 기법이다.
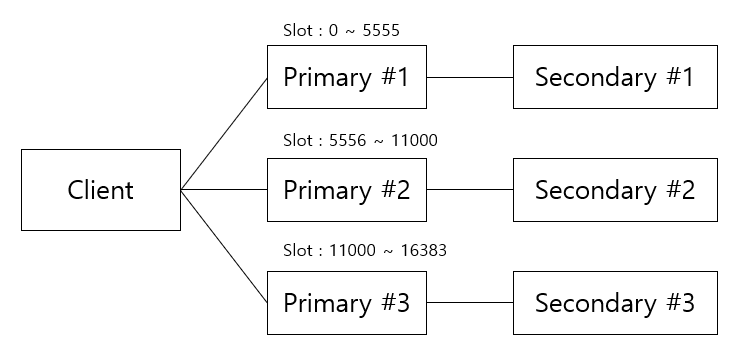
Redis Cluster 은 failover 를 위한 대표적인 구성방식 중 하나이다. Redis Cluster 은 여러 primary 가 Hash 기반의 slot 이 할당되어 있다.
primary 는 자기 slot range에 해당되는 키가 클라이언트로부터 도착하면 , OK 응답 후 저장한다. 하지만 요청은 받았지만 자기 슬롯에 해당하는 키가 아니면, -MOVED 에러를 송출한 뒤 해당되는 다른 primary 노드를 지정한 채로 다시 응답을 보낸다. 그럼 클라이언트는 다시 응답받은 primary 노드로 요청을 전송해야 한다. 이런 처리들도 결국 깔끔하게 구현하기 위해선 라이브러리가 필요하다.
Redis는 데이터의 이중화를 위해 secondary 를 가질 수 있다. primary 가 죽으면 secondary 가 primary 로 승격하여 역할을 수행한다. 그리고 primary 1 데이터가 변경되면 secondary 1 만 같이 변경되는데, 승격도 마찬가지이다.
장점
1) 자체적인 Primary / Secondary Failover (죽으면 자동으로 승격처리 된다.)
2) Slot 단위의 데이터 관리 : 이 키는 어디로 보내라 ~ 라는 명시적인 관리가 가능하다.
단점
1) 메모리 사용량이 더 많다.
2) Migration 자체는 관리자가 시점을 결정해야 한다.
3) 라이브러리 구현이 필요하다
참고
'컴퓨터 공학 > 데이터베이스' 카테고리의 다른 글
| MySQL / 사용자 계정 추가, 권한 부여하기 (0) | 2021.10.03 |
|---|---|
| 레디스(Redis)의 기본 명령어 (0) | 2021.08.31 |
댓글